
LLM Security Testing: Identifying Risks in Enterprise AI Applications
30 June 2026
Enterprise AI applications are transforming how organizations access knowledge, automate workflows, and improve decision-making. However, connecting large language models (LLMs) to internal data sources, APIs, business applications, and autonomous agents introduces a new class of security risks that traditional application security testing cannot fully address.
Enterprise Incident
A global financial organization deployed an internal AI assistant integrated with SharePoint, Microsoft Teams, CRM systems, and HR portals. During a security assessment, testers embedded an indirect prompt injection inside an uploaded document. When employees queried the assistant, the hidden instruction manipulated the retrieval pipeline and exposed confidential board documents. The incident demonstrated that conventional penetration testing missed AI-specific attack paths involving prompts, retrieval, and tool execution.
Enterprise LLM Attack Surface
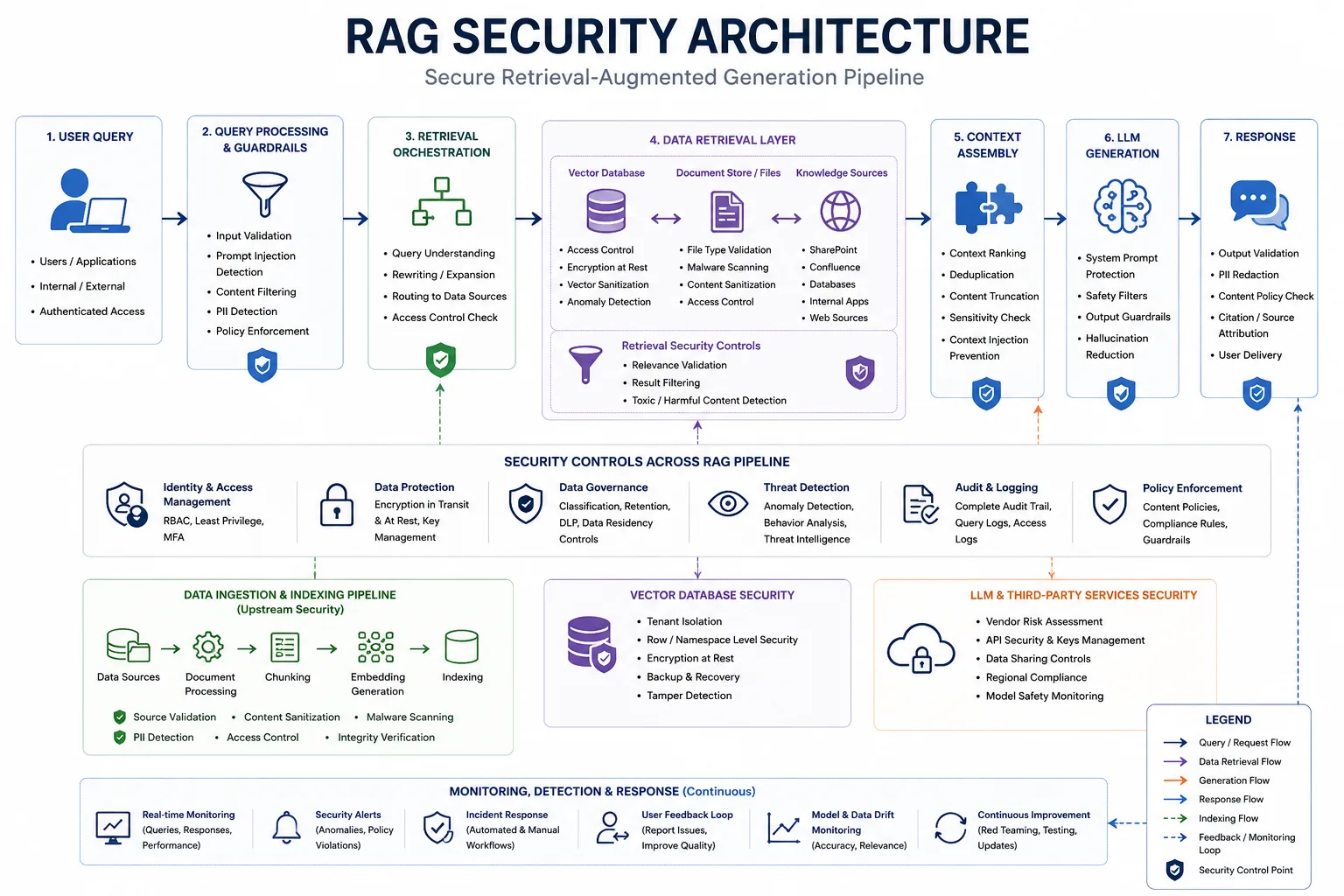
Every enterprise AI application consists of multiple attack surfaces: User → Prompt Processing → System Prompt → Memory → RAG Pipeline → Vector Database → Tool Calling → Enterprise APIs → Business Applications → LLM Response. Each layer can become an entry point for prompt injection, data leakage, privilege escalation, memory poisoning, or API abuse. Testing must evaluate the complete AI workflow rather than the model in isolation.
Threat Modeling
LLM threat modeling focuses on trust boundaries, identity, data flows, connected tools, plugins, agent memory, external content, and privileged APIs. Unlike traditional web applications, AI systems continuously consume untrusted natural-language input and dynamically invoke downstream services, making abuse paths more complex.
LLM Security Testing Methodology
A mature assessment follows six phases: Discovery, Threat Modeling, Attack Simulation, Security Validation, Risk Assessment, and Reporting. Discovery inventories models, prompts, APIs, data sources, and integrations. Threat modeling identifies abuse paths. Attack simulation validates prompt injection, jailbreaks, prompt leakage, and tool misuse. Validation confirms mitigations. Risk assessment prioritizes findings by business impact. Reporting provides executive summaries and technical remediation.
Core Security Tests
Organizations should perform Prompt Injection Testing, Indirect Prompt Injection, Jailbreak Testing, System Prompt Extraction, Prompt Leakage, Data Leakage Testing, Role Manipulation, Model Extraction, Hallucination Testing, Tool Invocation Abuse, API Abuse, Memory Poisoning, Multi-Agent Abuse, and AI Red Teaming. Each assessment should document objective, attack method, expected behavior, business impact, and mitigation.
RAG Security Testing
RAG Security examines vector databases, embeddings, retrieval logic, chunk integrity, unauthorized document access, knowledge poisoning, and context injection. Testers validate whether malicious documents influence responses or bypass authorization controls.
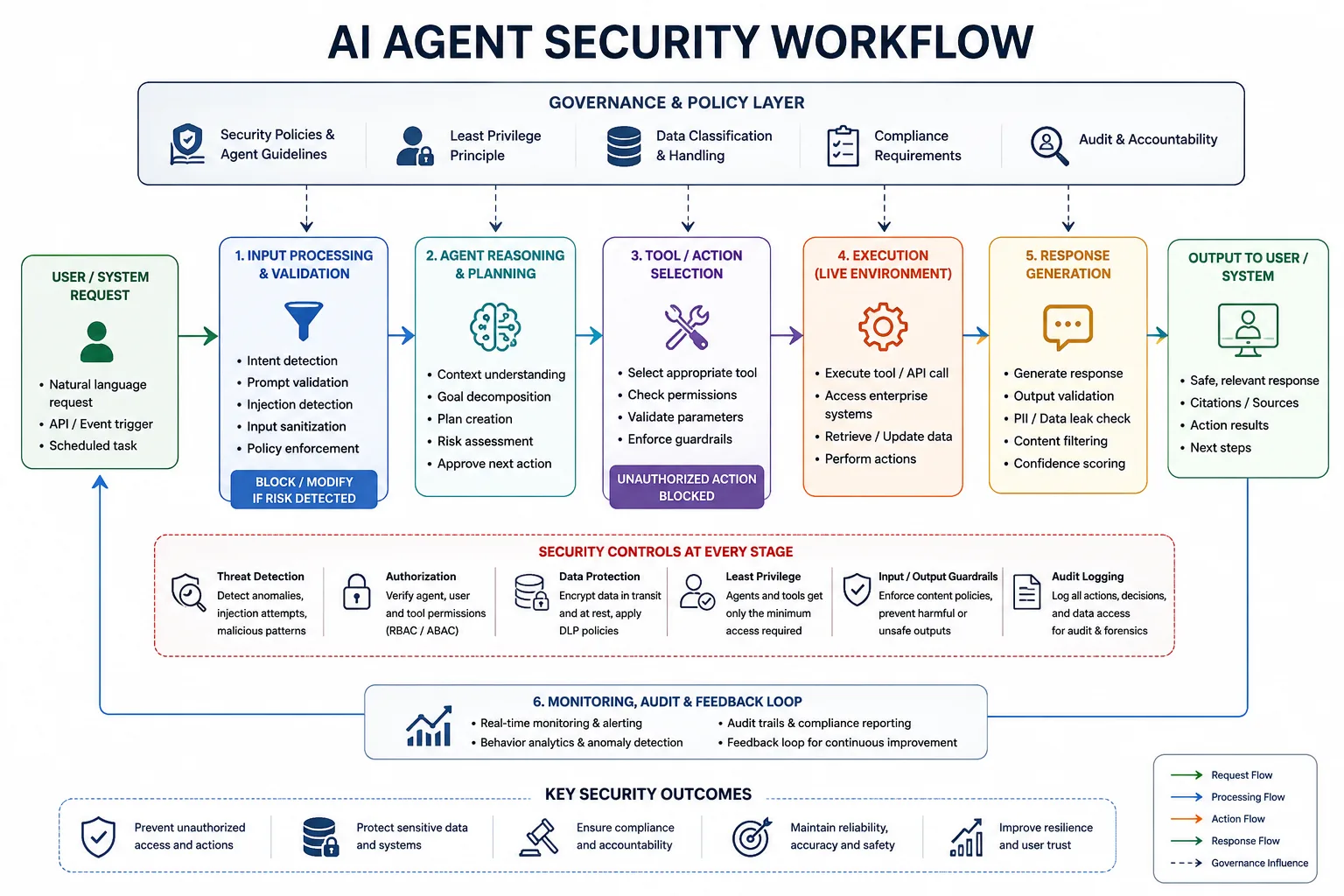
AI Agent Security
AI agents introduce autonomous execution risks. Assessments evaluate excessive permissions, unsafe tool invocation, API abuse, recursive planning, memory attacks, and privilege escalation. Human approval should be required for high-impact actions, while audit logs must capture every tool invocation.
Enterprise Maturity Model
Level 1 Experimental: ad hoc AI usage. Level 2 Basic: limited controls. Level 3 Managed: documented governance and testing. Level 4 Secure: continuous AI security testing, monitoring, and red teaming. Level 5 Optimized: automated validation integrated into the SDLC with measurable governance and executive reporting.
Common Mistakes
Common weaknesses include skipping prompt injection testing, trusting AI outputs without validation, exposing sensitive APIs, allowing Shadow AI, weak access control, inadequate monitoring, and the absence of an AI Governance Framework or AI Red Teaming exercises.
Best Practices
Adopt secure-by-design architecture, least-privilege access, continuous AI Security Testing, AI Security Assessments before deployment, centralized logging, AI Security Audits, governance reviews, vendor risk assessments, compliance mapping, and periodic red teaming aligned with recognized frameworks such as NIST AI RMF and the OWASP Top 10 for LLM Applications.
How Digital Defense Helps
Digital Defense supports organizations with LLM Security Testing, AI Security Assessments, Prompt Injection Testing, AI Red Teaming, AI Agent Security Assessments, RAG Security Assessments, AI Risk Assessments, AI Governance Reviews, and AI Security Audits to help identify and remediate AI-specific risks before production deployment.
Enterprise Security Testing Matrix
Enterprise AI applications require a comprehensive security testing strategy because they introduce attack vectors that do not exist in traditional software. The following testing areas help organizations evaluate the security posture of their Large Language Model (LLM) applications and prioritize remediation efforts based on business risk.
Prompt Injection testing evaluates whether an attacker can manipulate the AI model through carefully crafted instructions. This attack has high severity and high likelihood because user prompts are the primary interface to the model. Successful prompt injection can result in unauthorized data exposure, making input validation, prompt filtering, and context isolation essential security controls.
Indirect Prompt Injection focuses on malicious instructions hidden within external content such as documents, emails, websites, or knowledge bases that the LLM retrieves during processing. Although the likelihood is medium, the severity remains high because attackers can influence model behavior without directly interacting with it. Organizations should implement content sanitization, retrieval validation, and trusted data source verification to reduce this risk.
Prompt Leakage testing determines whether attackers can extract hidden system prompts, confidential instructions, or internal configuration data. This represents a medium-severity and medium-likelihood threat that may expose proprietary business logic or security policies. Prompt isolation, role separation, and output filtering are effective mitigation techniques.
Data Leakage Testing validates whether the model can disclose confidential customer records, internal documents, personally identifiable information (PII), or regulated business data. Since enterprise AI systems frequently access sensitive information, both the severity and likelihood are considered high. Strong identity management, role-based access control (RBAC), and data classification policies are critical defenses.
RAG Poisoning assesses whether attackers can manipulate a Retrieval-Augmented Generation (RAG) pipeline by inserting malicious or misleading information into vector databases or indexed documents. This attack carries high severity with medium likelihood, potentially causing inaccurate business decisions or misinformation. Content integrity validation, trusted indexing pipelines, and document verification should be implemented.
Memory Poisoning examines whether attackers can influence future AI responses by injecting malicious information into long-term or session memory. The risk is medium for both severity and likelihood because compromised memory can persist across conversations. Organizations should isolate memory, validate stored context, and periodically clear or verify retained information.
Tool Abuse testing verifies whether AI agents can be manipulated into invoking connected tools or business functions without proper authorization. Because many enterprise AI assistants integrate with email, databases, ticketing systems, and cloud services, the severity is high with a medium likelihood. Applying least-privilege access, authorization checks, and approval workflows significantly reduces this risk.
API Abuse evaluates whether attackers can exploit AI-integrated APIs through unauthorized requests, parameter manipulation, or excessive privileges. This represents a high-severity, medium-likelihood threat capable of compromising backend systems. Strong API authentication, authorization controls, rate limiting, and continuous monitoring are essential security measures.
Model Extraction testing determines whether an attacker can reconstruct proprietary models or infer sensitive training information through repeated interactions. While the likelihood is relatively low, the severity remains medium because intellectual property and competitive advantages may be compromised. Rate limiting, query monitoring, and response randomization help mitigate extraction attempts.
Hallucination Testing measures how frequently an AI system generates inaccurate or fabricated information under different conditions. Although hallucinations are not always malicious, they present a medium-severity and high-likelihood operational risk that can lead to incorrect business decisions, compliance violations, or reputational damage. Human review, confidence scoring, and retrieval validation are recommended safeguards.
Role Manipulation testing evaluates whether users can bypass authorization boundaries by persuading the model to assume privileged roles or ignore predefined restrictions. This attack has high severity and medium likelihood, potentially leading to privilege escalation and unauthorized access. Strong authorization logic, policy enforcement, and secure system prompts are required to prevent abuse.
Multi-Agent Abuse focuses on environments where multiple AI agents collaborate to complete tasks. Attackers may exploit communication between agents to trigger cascading failures, privilege escalation, or unauthorized actions. Although the likelihood is low, the severity is high because failures can propagate across interconnected workflows. Organizations should enforce communication policies, validate agent interactions, and continuously monitor multi-agent activities.
Collectively, these security tests form the foundation of a comprehensive LLM Security Testing program. By assessing each attack vector systematically, organizations can identify vulnerabilities early, prioritize remediation based on business impact, and strengthen the overall security and resilience of enterprise AI applications before they are deployed into production.